
The Open-Weights Upset: What GLM-5.2 Topping the Design Arena Leaderboard Signals for the Future of AI
GLM-5.2 has claimed the top spot on Design Arena's Code Categories Arena leaderboard with an Elo score of 1360 — and it's open weights. The essay examines what this means for the competitive AI landscape and who benefits when open models reach the frontier.
There is a specific kind of disruption that doesn’t announce itself with a press conference. It shows up as a number on a leaderboard — and then quietly reshapes everything you thought you knew about who controls the cutting edge of AI.
That’s what happened when a recent post on X from Design Arena announced that GLM-5.2 had climbed to the top of its Code Categories Arena rankings, achieving an Elo score of 1360. The model, developed by Zai.org, jumped four positions and added 27 Elo points to claim the functional number-one spot — pushing past Claude Fable 5 (1350), Claude Opus 4.6 (1342), and multiple other Claude variants that dominate positions two through five. The detail that makes this genuinely significant isn’t just the ranking itself. It’s that GLM-5.2 is open weights.
What the Leaderboard Actually Shows
Design Arena, run by The Intelligence Company, uses Elo scoring — the same system borrowed from competitive chess — to rank AI models on code-related tasks. Elo isn’t a static test score; it reflects performance relative to other models in head-to-head comparisons, which means climbing four positions with 27 additional Elo points represents a meaningful competitive improvement, not just a marginal numerical tick.
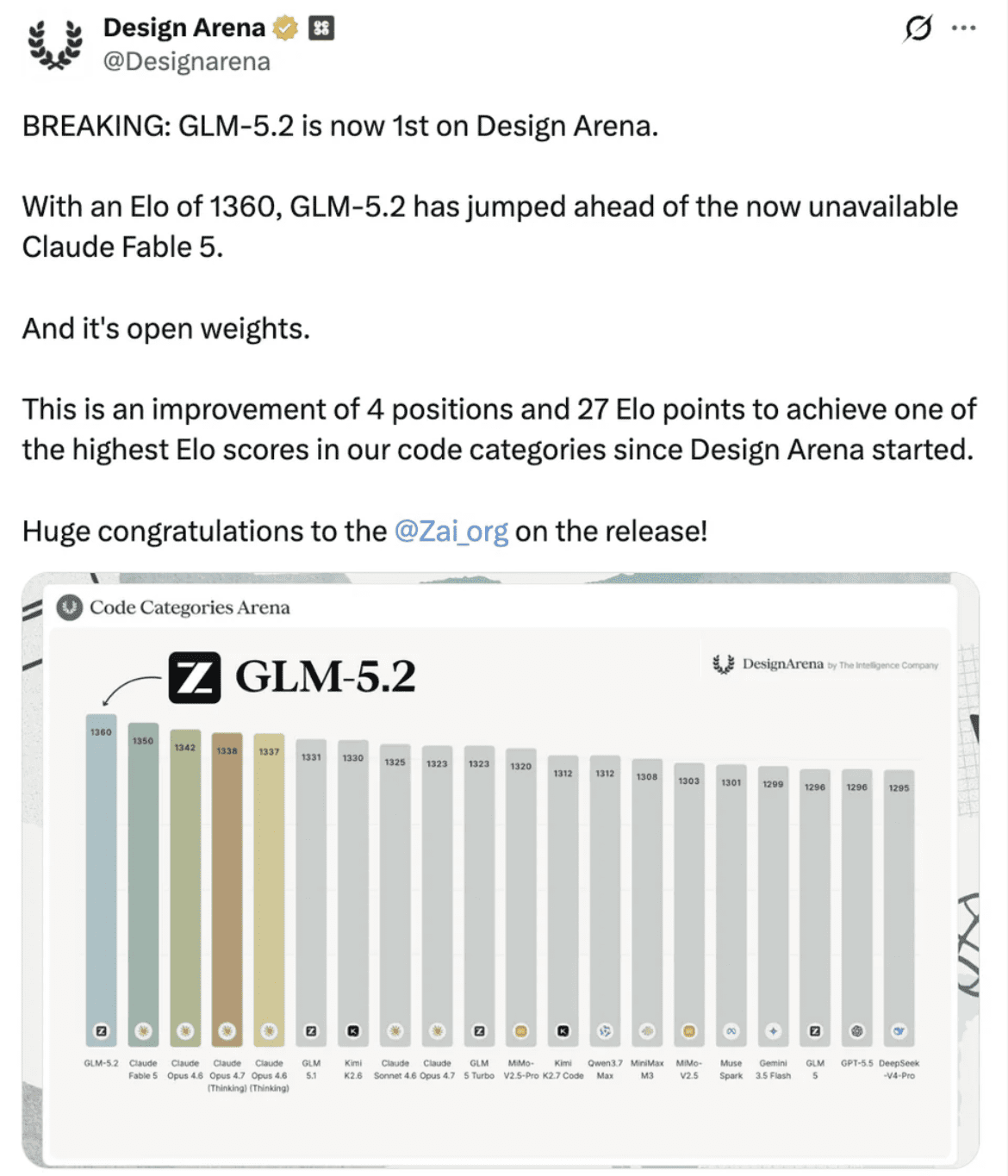
Looking at the full chart, what’s striking is the density of the competition at the top. The gap between rank one (GLM-5.2 at 1360) and rank twenty (DeepSeek-V4-Pro at 1295) is only 65 Elo points. The top ten models are separated by just 37 points. This is not a landscape where one model towers above all others — it’s a tightly clustered race where marginal improvements in architecture or training translate directly into leaderboard movement. In that context, a four-position jump is genuinely hard to achieve.
Also worth noting: the post flags that Claude Fable 5, previously holding the top position, is now listed as unavailable. GLM-5.2 didn’t just beat a static field — it now holds the highest active score among models users can actually access.
The Open-Weights Distinction Matters More Than It Sounds
The AI industry has a habit of treating ‘open weights’ as a philosophical preference — a nice-to-have for researchers and idealists, but not a serious competitive consideration when you’re comparing raw performance. The Design Arena ranking challenges that framing directly.
When an open-weights model reaches the top of a competitive leaderboard, it isn’t just a win for a single organization. It means the weights — the actual trained parameters of the model — are available for others to study, modify, fine-tune, and deploy. The performance ceiling isn’t locked behind an API. Teams that want to build on that capability don’t have to negotiate enterprise contracts or work around rate limits. They can run the model themselves.
For developers and product teams, particularly those operating in cost-sensitive environments or with specific deployment constraints, this distinction is enormously practical. Proprietary frontier models are powerful, but access to them is mediated — by pricing, by availability, by the decisions of the companies that own them. The fact that Claude Fable 5 is now listed as ‘unavailable’ on the leaderboard is an accidental illustration of this dynamic: when a proprietary model is pulled, it’s simply gone. An open-weights model, by contrast, persists. Once the weights are released, they exist independently of the organization’s product roadmap.
A Stronger Model Family, Not a Single Outlier
One of the more quietly significant details in the Design Arena post is that GLM-5.2’s rise isn’t an isolated event. Looking at the full top-twenty chart, the GLM family occupies four positions: GLM-5.2 at rank one, GLM 5.1 at rank six, GLM 5 Turbo at rank ten, and GLM 5 at rank eighteen. That is not the distribution of a team that got lucky with one model release. It reflects a sustained, systematic improvement across iterations.
This pattern — multiple variants of the same model family performing well across the leaderboard — is what distinguishes a genuine research trajectory from a benchmark-optimized one-off. The GLM lineage appears to be improving reliably across generations, which is a stronger signal than any single Elo score.
Compare this to how the rest of the leaderboard is structured. Claude models (Fable 5, Opus 4.6, Opus 4.7 in both standard and thinking variants, Sonnet 4.6, Opus 4.7) occupy positions two through nine, representing Anthropic’s continued dominance in the upper tier. But between GLM variants, Kimi models (K2.6 at rank seven, K2.7 Code at rank twelve), MiMo variants, and others, a significant portion of the top twenty is now occupied by models from organizations that weren’t household names in the AI conversation even a short while ago.
What Competitive Pressure at the Top Actually Produces
There is a reasonable argument that leaderboard competition of this kind is net positive for everyone — including users who never look at a benchmark chart. When multiple organizations are capable of producing models that compete at the top tier of performance evaluations, the pressure on any single organization to rest on its advantages disappears. Pricing tends to come down. Access tends to broaden. Capability improvements that might otherwise be held back as competitive moats get released faster because withholding them no longer guarantees an edge.
The tightly clustered Elo scores on the Design Arena chart — where twenty models occupy a 65-point range — suggest the industry is entering exactly this kind of competitive phase in code-related AI tasks. No single model has a commanding lead. Zai.org’s GLM-5.2 holds the top spot today; the post itself acknowledges this is an improvement of four positions, implying earlier iterations weren’t at the top. The leaderboard is dynamic.
For Indian professionals working in software development, product engineering, data science, or any discipline that involves writing, reviewing, or reasoning about code, this competitive dynamic has a concrete implication: the quality of open-access AI tools for coding tasks is rising. The assumption that the best code-generation capability lives exclusively behind the APIs of two or three US-based incumbents is becoming harder to sustain. GLM-5.2’s open-weights status means that if you or your team has the infrastructure to run it, the number-one ranked model on this particular leaderboard is accessible to you directly — not as a managed API, but as a model you can deploy and control.
The Leaderboard as a Map of What’s Coming
Elo rankings in AI benchmarks are, of course, imperfect. Design Arena measures performance on code-related design tasks specifically — this is not a claim about general intelligence, reasoning, or every use case. Different benchmarks tell different stories, and any single leaderboard reflects the particular choices its designers made about what to measure and how.
But the direction the chart points is instructive. The top twenty models come from a wider range of organizations than they did a year ago. Open-weights models are competing at the very peak of performance evaluations. The gap between the best closed proprietary models and the best open alternatives has narrowed to single-digit Elo points in some comparisons.
What the GLM-5.2 announcement represents, at its most consequential, is a proof point: that reaching the top of a serious competitive benchmark no longer requires the resources or the closed-development approach of the largest AI labs. That proof point, once established, tends to attract more investment, more talent, and more attempts to replicate and exceed it.
The number-one spot on a leaderboard changes. The shift in what that spot proves possible — that’s the part that doesn’t change back.





